StackEx DataDump Part: 2
Tags dataset has 300 different tags for various posts related to Data Science. Each tag has an associated count value with it.
Tags Table
| Id | TagName | Count |
|---|---|---|
| 1 | definitions | 15 |
| 2 | machine-learning | 1331 |
| 3 | bigdata | 224 |
| 5 | data-mining | 396 |
| 6 | databases | 38 |
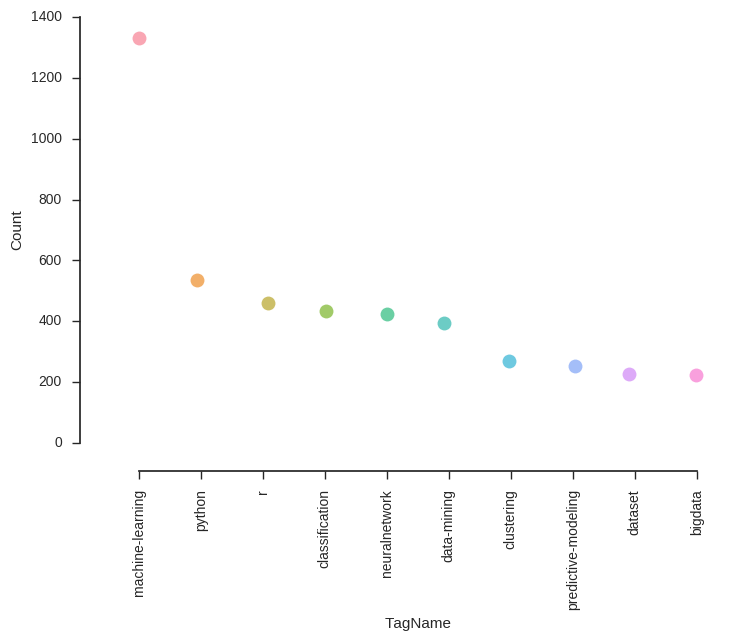
Top 10 Tags based on Count
Tags Table
| Id | TagName | Count |
|---|---|---|
| 1 | machine-learning | 1331 |
| 32 | python | 537 |
| 18 | r | 460 |
| 53 | classification | 435 |
| 56 | neuralnetwork | 425 |
| 3 | data-mining | 396 |
| 11 | clustering | 269 |
| 101 | predictive-modeling | 253 |
| 42 | dataset | 226 |
| 2 | bigdata | 224 |
Top 5 posts based on Score
- One of the common problems in data science is gathering data from various sources in a somehow cleaned (semi-structured) format and combining metrics from various sources for making a higher level analysis. Looking at the other people’s effort, especial (89)
- I’m using Neural Networks to solve different Machine learning problems. I'm using Python and pybrain but this library is almost discontinued. Are there other good alternatives in Python? (82)
- UPDATE: the landscape has changed quite a bit since I answered this question in July’14, and some new players have entered the space. In particular, I would recommend checking out: link1 (78)
- To me (coming from a relational database background), “Big Data” is not primarily about the data size (which is the bulk of what the other answers are so far). “Big Data” and “Bad Data” are closely related. Relational Databases require (63)
- Lots of people use the term big data in a rather commercial way, as a means of indicating that large datasets are involved in the computation, and therefore potential solutions must have good performance. Of course, big data (53)
Top 5 posts based on number of comments
- I have a large set of points (order of 10k points) formed by particle tracks (movement in the xy plane in time filmed by a camera, so 3d - 256x256px and ca 3k frames in my example set) and noise. These particles travel on approximately straight lines ro (19)
- I am a PhD student of Geophysics and work with large amounts of image data (hundreds of GB, tens of thousands of files). I know
svnandgitfairly well and come to value a project history, combined with the ability to easily w (18) - It seems as though most languages have some number of scientific computing libraries available.
PythonhasScipy,RusthasSciRustC++has several in (17) - It is used for several reasons, basically it’s used to join multiple networks together. A good example would be where you have two types of input, for example tags and an image. You could build a network that for example has: IMAGE -> Co (16)
- Logic often states that by overfitting a model, its capacity to generalize is limited, though this might only mean that overfitting stops a model from improving after a certain complexity. Does overfitting cause models to become worse regardless of the (15)